
Google検索エンジンの仕組みとSEOで注意すべきポイント

この記事で分かること
- Google検索エンジンの基本的な仕組み
- 仕組みの観点からSEOで注意すべきポイント
この記事では、現在Webサイトの管理者であるか、またはビジネスのために個人のブログやWebサイトを作成することを検討している方に向けて、検索エンジンがどのように機能するかを解説していきます。
検索エンジンが理解しやすいWebサイトを作成するには、検索の仕組みを明確に理解する必要があります。
これは、SEOやその他の検索エンジンマーケティング(SEM)タスクに取り組む前に、最初に行う必要がある学習の第一ステップです。
特にこれからSEOを開始しようと考えている方は是非参考にしてみてください。
検索エンジンとは?
検索エンジンとは、インターネット上のWebサイトを検索するためのオンラインツールであり、ユーザーが入力した検索クエリに基づいて検索結果を表示するように設計されています。
独自のデータベースを使用して結果を検索し、それらを並べ替え、独自の検索アルゴリズムを使用して検索結果の順位付けされたリストを表示します。
この順位付けリストは、検索エンジンの結果ページ(SERP、もしくはSERPs)と呼ばれています。
世界中には、Google、Bing、Yahoo!など様々な検索エンジンがありますが、これらの検索と回答の一般原則は、すべての検索エンジンで同じです。
下記は国内における、検索エンジンのシェア率です。
| Yahoo! | bing | その他 | |
|---|---|---|---|
| 75.86% | 13.4% | 9.61% | 1.13% |
検索エンジンの歴史
- 最初のインターネット検索エンジンは、1990年に導入されたArchie Query Formでした。この検索エンジンはFTPサイトを検索し、シンプルなツールを用いてリスト形式で情報を提供することができましたが、その他の情報は含まれていないものでした。
- 1996年に導入された検索エンジンであるBackRubが現在のGoogleの前身です。この検索エンジンは、被リンクの基本原理を導入し、現在でも使用されているPageRankアルゴリズムの基礎を築きました。
- BackRubの後継であるGoogleは1998年に設立され、長年にわたって世界で最も人気な検索エンジンとなりました。
Google検索エンジンの仕組み
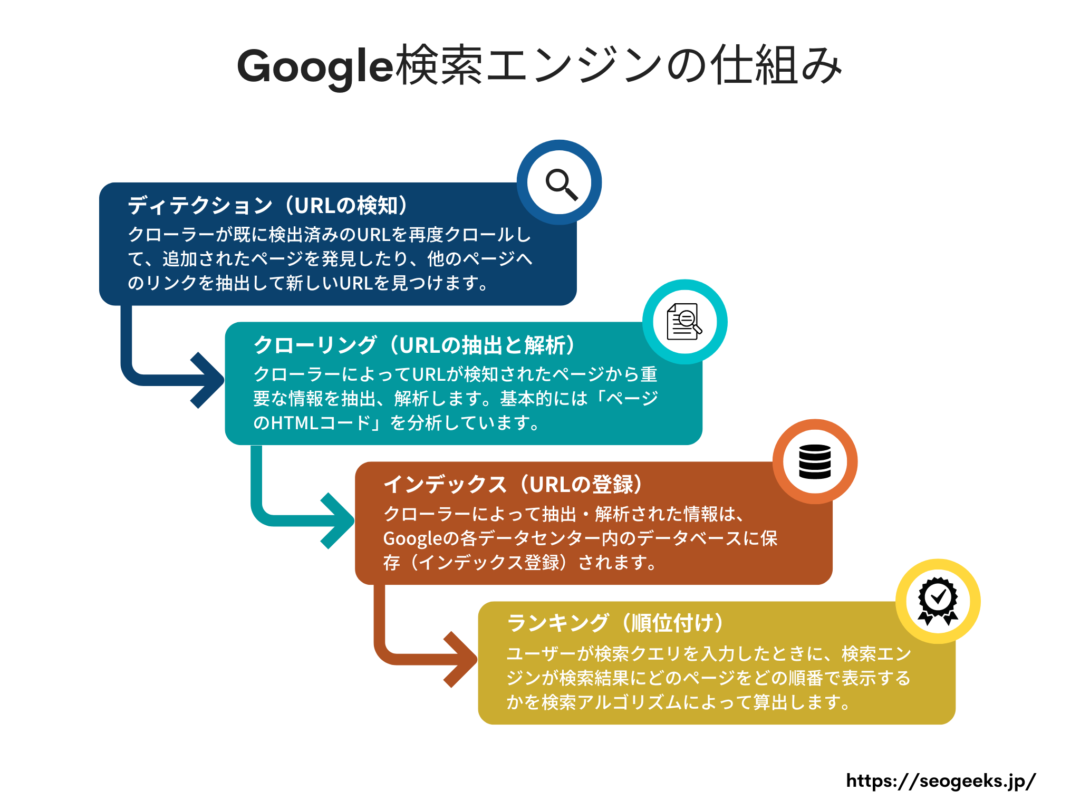
各検索エンジンがユーザーに検索結果を返す方法はそれぞれ異なりますが、すべてが同様の4つの基本原則に基づいて作られています。
- ディテクション(URLの検知)
- クローリング(URLの抽出と解析)
- インデックス(URLの登録)
- ランキング(順位付け)
検索エンジンの仕組み①:ディテクション(URLの検知)
Googleの検索エンジンがWebサイトを発見するための最初のステップである、ディテクション(URLの検知)の解説からスタートです。
まず、検索エンジンには、Webサイトを検索するためのコンピュータープログラムである「クローラー」と呼ばれるものが多数存在します。
これらは、インターネット上に公開されている情報を自動的に収集(クロール)する役割を担っています。
ちなみにGoogleのクローラーはGooglebot(グーグルボット)と呼ばれています。
このクローラーは、既に検出済みのURLを再度クロール(クローリング)して、追加されたページを発見したり、他のページへのリンクを抽出して新しいURLを見つけます。
そして、これらの新しいURLはクロール待ちのリストに追加され、後に実際のクローリング(URLの解析)が実行されます。
クローラーがURLを検知する方法
クローラーがURLを検知する方法としては全部で4つあります。
sitemap.xmlを送信する
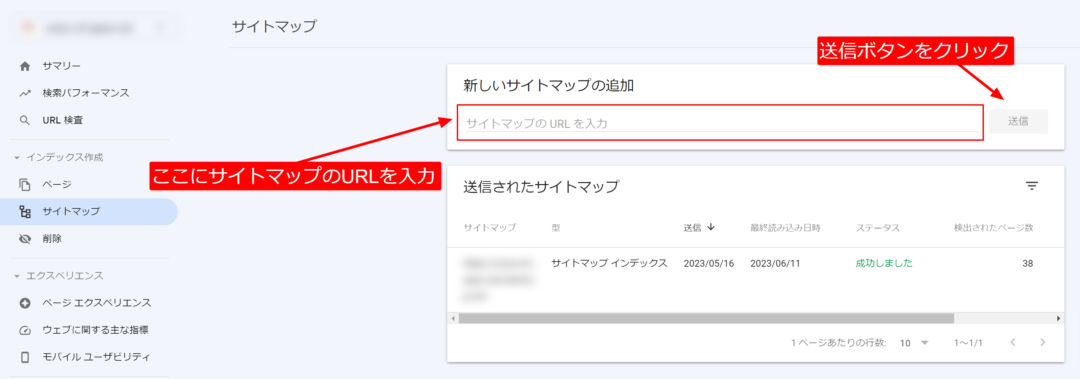
1つ目の方法は、サイトマップを送信することで、これはGoogleサーチコンソールで行うことができます。

サイトマップを作成する方法としては、自分で作成するか、専用の作成ツールを使用するか、2つの方法があります。
例えば、WordPressでWebサイトを持っている場合、新規プラグインの検索欄に「xml sitemap」と入力すると、便利なサイトマップ生成プラグインが見つかります。
Googleサーチコンソールにサイトマップを送信すると、GoogleがどのWebサイトを認識してインデックスに登録する必要があるかを伝えることができます。
サイト全体に大きな変更を加えたり、サイトを新しく作成した場合などは、すぐにサイトマップを送信してください。
これにより、GoogleでURLが検知されるスピードを早くできます。
サイトマップURLの例:https://example.com/sitemap.xml
Googleにとってサイトマップは、サイト全体のURLに関する重要な情報源です。
インデックス登録のリクエスト
サーチコンソールを使ってページをクロール待ちのリストに追加することは、クローラーに対してURLを検知してもらうための最も迅速かつ簡単な方法です。
検査バーにクロールさせたいページのURLを入力し、「インデックス登録をリクエスト」ボタンをクリックしてください、数秒から数分でリクエストが完了します。
あとはクローラーがURLを検知し、ページをクローリングしてくれるのを待つだけです。
この方法は、特定のページに変更があった場合、例えば1つの記事の内容を変更した場合や、新しいブログ記事を公開した場合など、単一ページの通知に役立ちます。

Indexing API
Indexing APIとは、ページの追加や削除があった場合にWebサイトの所有者からGoogleへ通知ができるAPIサービスです。
これにより、GoogleがWebページのクローリングをスケジュールできるようになり、定期的にクローラーがWebサイトに訪問されるようになります。
Indexing APIを使用することで、1日あたり1つのアカウントから最大200件のURLをクロール待ちのリストに追加できます。
Indexing APIで利用できる機能としては次のとおりです。
- URLの更新:新しいURLをGoogleに通知して、以前に送信されたURLのコンテンツをクロールまたは更新できます。
- URLの削除:ページが削除されたことをGoogleに通知すると、Googleはそのページをインデックスから削除します。そして、そのURLを再びクロールしないようにできます。
- リクエストステータスのチェック:Googleが最後に受信した、指定されたURLに関する各通知情報(ステータス)を確認できます。
- 一括クロールリクエスト:1回のリクエストで最大100個のリクエストを送信することで、本来必要とする通知数を減らすことができます。
Googleは、サイトマップの代わりにIndexing APIを使用することを推奨しており、これによりGooglebotがページをより速くクロールできるようになります。
サイトマップではなく Indexing API を使用することをおすすめします。これは、サイトマップを更新して Google に送信するよりも、Indexing API を使用した方が、Googlebot がすぐにページをクロールするためです。その場合でも、サイト全体をカバーするためにサイトマップを送信することをおすすめします。
Indexing API クイックスタート – Google検索セントラル
しかし、Indexing APIの導入にはGoogle Cloud Platformに関する知識が必要なので、自身で導入するのが難しい方は、前述したサイトマップを使用した運用で問題ありません。
大量のページが存在するECサイトや、情報鮮度の変化が激しいニュースサイトや求人ポータルサイトなど運営している方は、これを機にIndexing APIを導入してみてください。
内部リンク
ページ内に設置された内部リンクは、ユーザーとクローラーのどちらにも、サイト内に追加のページ(URL)が存在することを示してくれます。
また、後に説明するGoogleがページをクローリングしてインデックス登録を行う際、内部リンクが適切に配置されていることが非常に重要です。
これにより、インデックス登録のプロセス速度が大幅に向上します。
外部リンク
外部リンクも内部リンクと同じように、クローラーが新しいURLを検知するのを手助けします。
特にインデックスが既に登録されていて、かつトラフィックが多いページからの被リンクは、インデックスの登録プロセスを早くすることができます。
検索エンジンの仕組み②:クローリング(URLの抽出と解析)
クローリングとは、クローラーによってURLが検知されたページから重要な情報を抽出、解析するプロセスになります。
クローリングするには、ページをレンダリングする必要があり、ページのコードを実行し、ユーザーにとってページがどのように見えるかをクローラーが理解することで、解析作業が行われます。
レンダリングやコードの実行といった少し専門的なワードを使いましたが、基本的には「ページのHTMLコード」を分析していると考えてもらって大丈夫です。
クローリングの詳細なプロセスは外部に公開されていないので、Googleの社員でない限り、詳しい内容は誰にもわかりません。
サイト所有者がクローリングのプロセスで気をつけておくべきこととしては、クローラーがすべてのサイトに対して平等に作業リソース(時間と計算能力)を割いてくれない点です。
クローラーがサイトに対して費やすリソースの割合のことを「クロールバジェット」と呼び、主に以下の要因によってリソースが決定されます。
- robots.txtリクエストの失敗率
- DNSサーバーの応答率
- サーバー接続時の応答率
上記の各パラメーターは、サーチコンソールの「クロールの統計情報」で確認できます。
詳しくは、ホストのステータスの詳細 – Search Console ヘルプを確認してみてください。
このクロールバジェットに関する情報は、Googleがヘルプページで、「サイトのページ数が1,000未満の場合は気にしなくても大丈夫」と記載していますので、該当する方は気にしなくても問題ありません。
検索エンジンの仕組み③:インデックス(URLの登録)
クローラーによって抽出・解析された情報は、最終的に検索ユーザーが利用できるようになる前に、Googleの各データセンター内のデータベースに保存しておく必要があります。
このプロセスをインデックス登録、またはインデックス作成と呼びます。
Googleのデータセンターとは?
Googleデータセンターは、強力なサーバーリソースを集中させ、世界中の膨大な量のデータを収集して処理する場所です。
Googleは、24時間途切れることのない情報の流れを確保するためにデータセンターを各国に設置しています。
Googleデータセンターは、検索エンジンのデータだけでなく、Googleが提供するすべてのサービス、例えばGmail、YouTubeなどのデータも取り扱っています。
ちなみに日本では千葉県印西市にデータセンターが設置されています。
検索エンジンは、ページで見つかったすべての情報をインデックスに登録するわけではなく
- ページの作成日や更新日
- ページのタイトルと説明文
- コンテンツの種類
- キーワード
- 被リンクと発リンク
- その他アルゴリズムに必要な多くのパラメータ
上記のような要素を考慮して、インデックスに登録するかどうかの評価、判断を行います。
肯定的に評価されたページはGoogleのデータベースに保存(インデックス登録)され、最終的に検索結果に表示されるようになります。
対照的にインデックスに登録されていないページは、ブラウザバーにURLを直接入力するか、ページへのリンクを直接クリックすることによってのみアクセスできます。
つまり検索エンジンでは表示されないということになります。
インデックスされているか確認する方法
ページがインデックスされているかどうかは、下記の3つの方法で確認することができます。
site:検索コマンドを実行する
この方法はインデックス登録の有無を最も容易に確認できますが、精度は低くなってしまいます。
しかし、Googleの検索エンジンでインデックス登録されたページの数を大まかに確認することができます。
この検索コマンドは、Googleが特定のURLを認識しているかどうかを確認できますが、必ずしもそのURLがインデックスに登録されているかどうかを確認できるわけではありません。
やり方としては、Googleの検索バーに下記のように確認したいURLを入力するだけです。
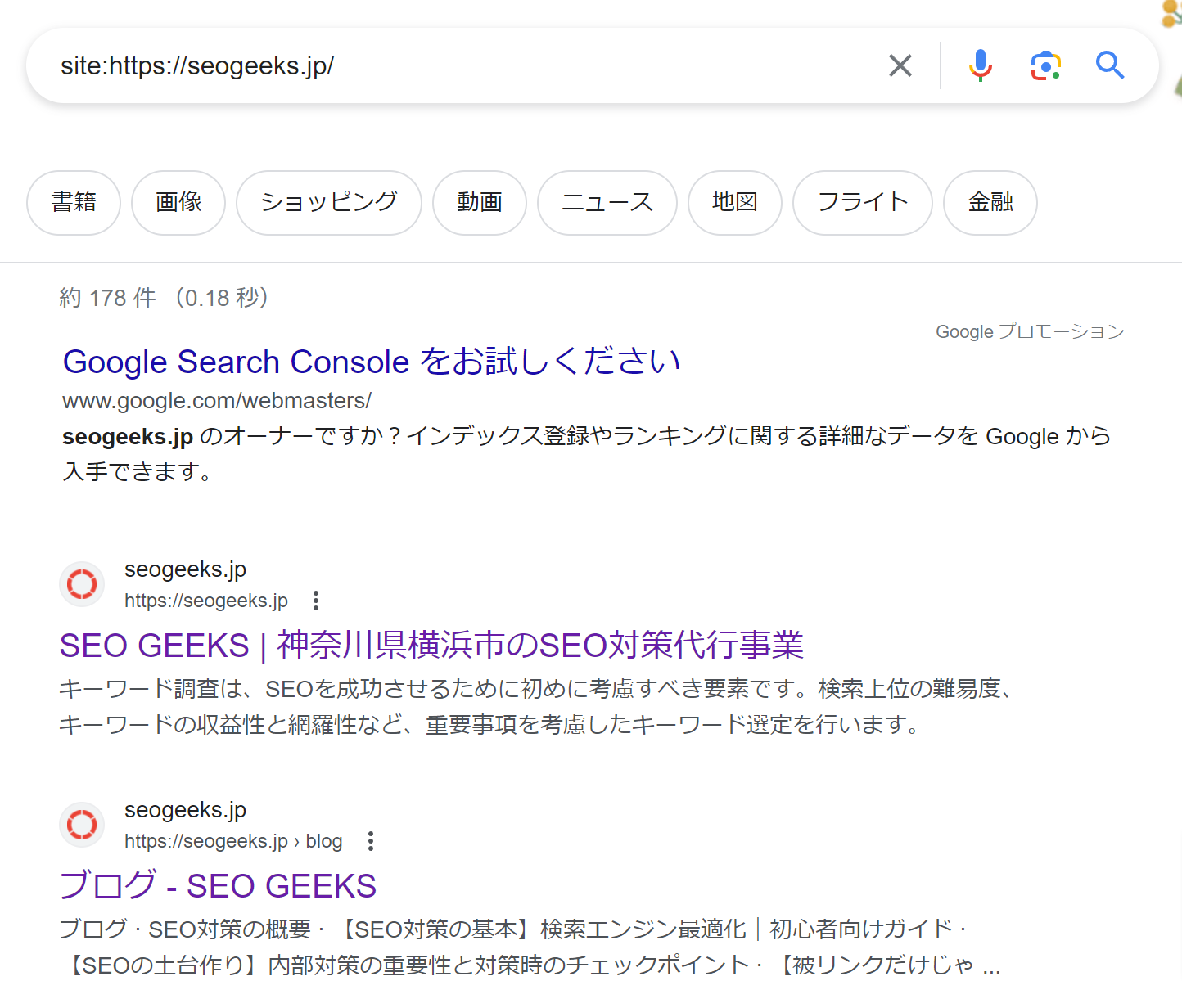
site:検索コマンドの例:site:https://seogeeks.jp/
cache:検索コマンドを実行する
cache:検索コマンド(例:cache:https://seogeeks.jp/)をGoogle検索で実行します。
これにより、Googleに保存されたページのキャッシュデータを確認できます。
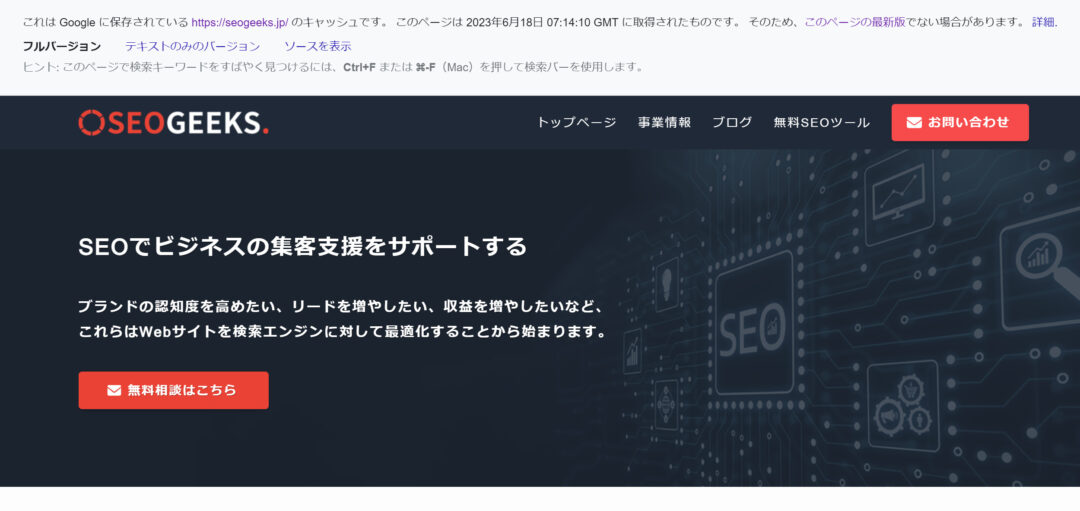
下記のようにページのキャッシュデータを確認できない場合、ページがGoogleにインデックスされていない可能性があります。

ただし、インデックス登録されたすべてのページが、必ずしもキャッシュ内にページ情報が保存されるわけではありません。
「キャッシュ内にページ情報が存在している=インデックスに登録されている」とはならないことに注意してください。
このあと説明するサーチコンソールでの確認ができない場合は、この方法が最も精度が高いのでおすすめです。
Googleサーチコンソールで確認する
この方法が最も精度が高く、信頼できる確認方法です。
サーチコンソールの検査バーに確認したいURLを入力し、Enterキーを押します。
これにより、ページのインデックス状況と、その他ページに関する様々な情報を確認できます。
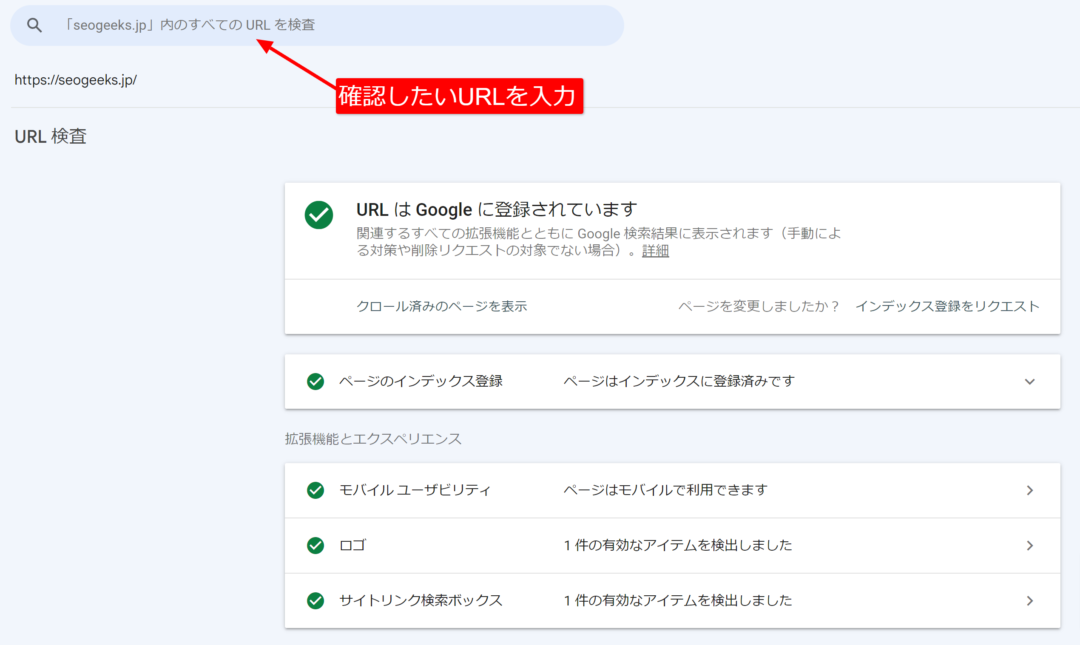
補足として、一般的にサーチコンソールは米国にあるメインデータセンターから情報を取得し、表示しています。
サーチコンソールが「URLはGoogleに登録されています」と表示しても、手動で確認した際にURLが検索結果に表示されない場合があります。
なぜなら、情報を収集するデータセンターがまだデータベースを更新していない可能性があるからです。
ページがインデックスされない一般的な理由
ページがGoogleのインデックスに登録されない理由はいくつかありますが、サイト所有者の視点から見ると、いくつか自身で原因を確認、解決できる方法があります。
robotsメタタグ
robotsメタタグは、検索エンジンが自身のサイトの要素をクロールまたはインデックスすべきかどうかに関する指示をすることができるタグになります。
ページがインデックスされない最も多い理由が、このrobotsメタタグの設定ミスによるものです。
<html>
<head>
<meta name="robots" content="noindex">
</head>
</html>上記のようにrobotsメタタグに対してcontent=”noindex”を設定すると、ページをインデックスしないよう、クローラーに指示することができます。
ページのソースコードを確認して、robotsメタタグにどのような設定をしているか確認してみましょう。
robots.txtファイル
インデックス登録されない、もう一つの主な理由は、robots.txtファイル内にクローラーをブロックする指示を記載していることです。
# すべてのクローラーをブロックする指示
User-agent: *
Disallow: /
# Googlebotのみをブロックする指示
User-agent: Googlebot
Disallow: /Webサイトがクローラーをブロックしていないことを確認するには、Googleが提供するrobots.txt テスターツールを使用して確認すると良いでしょう。
404エラーと301リダイレクト
Googleのインデックス登録に悪影響を与える可能性があるもう一つの要素は、404エラーや過剰な301リダイレクトです。
まず、404エラーを返すページは、ページが存在しないか利用できないことをクローラーに伝えます。
Googleのクロールプロセスにとって、特定のURLから返されるHTTPステータスは重要です。
もしページが40Xコード(例:404 – ページが見つかりません)や50Xコード(例:500 – 内部サーバーエラー)などのエラーを示すステータスコードを返した場合、Googleはそのページのクロールを中断します。
Googleは、ステータスコードが有効なもの、つまり200に変更されるまで待機することになります。
次に301リダイレクトは、URLの変更やサイト構造の変更に役立つことがありますが、使い過ぎるとクロールバジェットに悪影響が出る可能性があります。
ページ上のリダイレクトが多ければ多いほど、クローラーがサイト内のページ間を移動するのに費やす時間とリソースが増えてしまうのが理由になります。
canonicalタグ
「canonicalタグ」は、Googleがクロールする際に、サイト内の重複するページの中で優先的にクロールするべきページを示すために使用されます。
しかし、canonicalとして設定されたページが、存在しない別のページを指している場合、Googleのクローラーが混乱し、インデックス登録に問題が発生する可能性があります。
孤立ページ
サイト内には、内部リンクによってリンクされていないページが存在することがあります。
つまり、他のページからのリンクがない「孤立したページ」です。
このような孤立したページは、ユーザーがそのページに辿り着かないのと同様に、Googleのクローラーもそのページの存在を発見できない可能性があります。
検索エンジンの仕組み④:ランキング(順位付け)
最後のステップが、ユーザーが検索クエリを入力したときに、検索エンジンが検索結果にどのページをどの順番で表示するかを決定することです。
これらは、Googleの検索アルゴリズムによって算出されています。
Googleの検索アルゴリズムは、Google検索を行った際に、検索結果で表示される様々なサイトを順位付けするために使用される、一連のランキングシステム、プログラムのことです。
各サイトページからデータを取得して、検索者が何を探しているか(検索意図)を理解し、情報の関連性と品質に基づいて評価、順位付けを行います。
Googleの検索アルゴリズムは、一つのアルゴリズムだけでなく、複数のアルゴリズムで構成されており、順位付けを行うための評価項目は約200種類以上あると言われています。
Googleはこれらのアルゴリズムに関する詳細な情報を外部に公開していません。
ですが、Googleが公開しているランキング結果 – Google 検索の仕組みのページで、大まかではありますが、主要な5つの評価項目を紹介しています。
- 検索クエリの意味:検索エンジンはまず、ユーザーが使用した言葉を正確に理解すること、検索意図は何か、などを理解します。
- コンテンツの関連性:検索エンジンは、そのページが検索クエリに答えているかどうかを分析し、評価します。
- コンテンツの質:アルゴリズムは、Webページが優れた情報源かどうかを判断するために、内部および外部的な要因に基づいて判断します。その中で、被リンクの品質と数が重要な要素です。
- Webサイトのユーザビリティ:ページの操作性、ページの表示速度、セキュリティなど、技術的な観点からWebページの品質を考慮します。
- コンテキストと設定:ユーザーの現在地、検索履歴、好みなど、ユーザーから収集した情報は、最も関連性の高い検索結果を提供するために使用されます。

検索エンジン最適化とは?
検索エンジンは、ユーザーに有益な情報を提供するだけでなく、自身が所有するWebサイトを宣伝する手段でもあります。
関連する検索クエリに対してサイトを最適化することで、Webページへのトラフィックを増やせるため、オンラインマーケティング戦略において重要な役割を持っています。
Webサイトの管理者が、検索順位を上げるために行う作業やテクニックのことをSEO(検索エンジン最適化)、またはSEO対策と呼びます。
SEOには大きく分けて3つの対策があります。
- 内部対策:ページ内の技術的な最適化
- コンテンツ対策:検索意図に対してコンテンツを最適化
- 外部対策:ページの外的要因に対する最適化
このサイトでもSEOに関する様々な記事を公開していますが、これからSEOを学びたいという方は、まず下記の記事から読んでみてください。
検索エンジンに関するよくある質問
なぜGoogleが最も人気のある検索エンジンなのですか?
Googleは、長年にわたり検索エンジン市場のトップであり、現在でもその地位を維持しています。
Googleが最も広く使用されている理由は、いくつかあります。
- 最初の検索エンジンの1つである
- 適切な結果を提供する
- 高速である
- 常に改善されている
- いくつかの無料サービスに接続されている
検索エンジンが収益を上げている方法は?
Googleなどの検索エンジンの主な収入源は、様々な間接的なソースからです。
検索エンジンは、以下の方法でサービスから収益化することができています。
- 広告:Googleは、独自の広告サービスであるGoogle広告を使用しています。このサービスにより、企業は自社の商品を検索結果に表示することができ、ユーザーが広告をクリックするたびに少額の手数料をGoogleが受け取ることができます。
- オンラインショッピング:検索エンジンは、拡張された検索結果でさまざまな商品を宣伝することができ、ユーザーがその商品をクリックしたり購入したりすると、検索エンジンは代わりに購入額から少額の手数料を受け取ることができます。
- その他サービス:Googleは、自社で提供しているサービス(Playストア、Google Cloud、Google Workspaceなど)に独自の検索エンジンを組み込んでおり、これを利用する顧客を通じて収益を得ています。
最初の検索エンジンはなんですか?
最初のインターネット検索エンジンは、1990年に導入されたArchie Query Formでした。
この検索エンジンはFTPサイトを検索し、シンプルなツールを用いてリスト形式で情報を提供することができましたが、その他の情報は含まれていないものでした。
Webブラウザと検索エンジンの違いはなんですか?
Webブラウザとは、コンピュータやスマートフォンにインストールされているアプリケーションのことで、ChromeやFirefox、Microsoft Edgeなどが代表的な例です。
このブラウザの役割は、使いやすい画面を提供して、Webページを閲覧することです。
検索エンジン(Google、Bing、Yahoo!など)は、Webブラウザを介してアクセスできるオンラインツールです。
検索エンジンの目的は、ユーザーの検索に関連するWebページを関連性の高い順に表示することです。
簡単に言えば、WebブラウザはWebページにアクセスして表示するためのツールであり、検索エンジンは特定の情報を探すためのツールです。
まとめ
本記事では、Googleの検索エンジンがインターネット上に存在するWebサイトのデータをどのように発見、収集し、検索ユーザーに対して適切な検索結果を返すまでの一連の流れを紹介しました。
Googleは日々、世界中に存在する膨大な量のデータを取り扱っています。
なので、Webサイトの管理者がまず行うべき仕事としては、検索エンジンがシンプルで理解しやすい構造のサイトを作成することにあります。
これにより、Googleが行うクロールとインデックス登録の作業を手助けすることができます。
最後にこの記事が参考になった、あるいはご質問などがある方は、ぜひコメント欄でお聞かせください。
コメント